2023. 10. 23. 15:01ㆍR, 빅데이터 분석 실험
이건 애초에 못푼다.
미지수가 n개가 있을때 적어도 n개의 식이 있어야 풀린다.
하지만 미지수의 개수가 무수히 많은 것이고 식이 부족한 상황인 것이다.
완전하게는 아니지만 어떻게 풀 수 있을까?
이 글은 이 의문을 해소할 것이다.
먼저 실생활에서 이러한 문제가 무엇이 있을까? (데이터보다 독립 변수가 많은 경우)
-> 유전자 분석. 받는 사람은 적은데 유전자의 개수가 많음
실제 OLS(기존 최소 제곱법 : 선형 회귀 분석)으로 접근했을 때 무슨 문제가 발생할까?

결론으로 β를 찾기 위해 (X^tX)^-1X^ty 를 계산해야하는데 이 식이 오는게 X^tXβ = X^ty 에서 좌항에 역행렬을 곱하는 것이다.
그런데 X^tX가 역행렬이 존재해야 이 연산을 할 수 있다. p가 n 보다 작을때는 서로 다른점이라고 할 때 pull-rank인 고차원에서 저차원으로 이동하면서 역행렬이 존재할 수 밖에 없지만 p가 n보다 크면 pull-rank 저차원이 고차원으로 가는거라 역행렬이 존재할 수 없다.
따라서 기존의 OLS를 적용할 수 없다.
근데 그럼 p와 n이 같을때 OLS를 사용해도 괜찮을까?
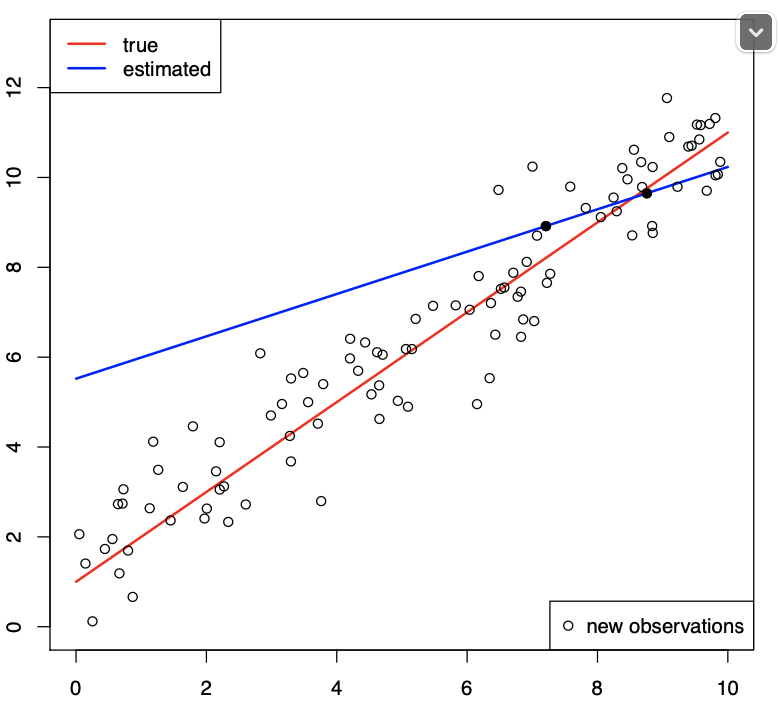
p와 n이 2인 경우가 파란색 선이다.
선이 그어질 수 있는 여러 경우의 수 중에서 오차가 최소인 구간을 구하는게 best인데 선이 그어지는 경우가 1가지 밖에 없게 된다.
2차원이아니라 3차원에 3개 점이라면 ? 선을 긋는 경우가 각 점을 잇는 한가지 경우밖에 없을것이고 100차원에 100개의 점이라도 그렇다.
따라서 p와 n이 어느정도 차이가 있어야 좋다.
이제 처음 질문으로 돌아와서 답을 생각해보자.
1. 중요한 p를 선별해서 차원을 줄인다.
2 몇몇 p를 계산에서 배제할 수 있도록 만든다. 즉 비용함수를 계산할 때 p가 0이되도록 식을 구성한다.
3. p를 합쳐서 차원을 줄인다.
각각의 기법을 best subset selection, penalized estimation , dimension reduction이라고 부른다.
1. best subset selection (BIC , EBIC)
가정 : p개의 독립변수중 실제 영향을 미치는건 몇 개 없다.
주의 사항
-> 기존 통계학적 변수 선택 기법을 사용해서는 안된다. 각 변수별로 귀무가설을 세워 검정통계량을 구하는 방식은
필연적으로 오류가 발생한다. 선택에 있어 실패할 확률이 조금씩 존재하고 그러한 오차들이 데이터가 많아지면서 점점 커지게된다.
(type1 error , type2 error 발생).
하는 방법
-> 1~p개까지의 독립변수를 선택하는 모든 경우에 따른 비용함수 값을 구한다. (만약 p가 n보다 크다면 1~n개까지)
그 중 가장 비용이 작은 경우를 구해 실행한다.
단점: 매우 많은 경우의 수에 대해 비용 함수값을 구해야하니 시간이 오래걸린다.
pC0 + pC1 + pC2 + … + pCp = 2^n개의 비용함수를 구해야함. (만약 p가 n보다 크다면 1~n개까지)
2.penalized estimation (ridge, lasso)
-> 식 y = b0 + b1x1 + b2x2 … 에서 b1가 0이라면 식에서 b1x1이 사라진다.
그래서 패널티를 걸어 b가 0이 되도록 만든다.
3.dimension reduction
-> 굳이 0이라고 하지 말고 몇몇 변수중 같은 b를 찾아서, 혹은 같다고 가정해서 모수의 차원을 줄이자.
p차원 변수 공간을 m차원 서브공간으로 투영한다. (m<p)
'R, 빅데이터 분석 실험' 카테고리의 다른 글
| 코드 정리 (0) | 2023.10.25 |
|---|---|
| [R] logistic regression anlysis of mass data (1) | 2023.10.23 |
| logistic regression anlyasis of massive data (1) | 2023.10.23 |
| method to find β of logistic regression anlysis (1) | 2023.10.22 |
| [R] 로지스틱 회귀 분석 실습 (0) | 2023.10.22 |